



Table of contents
Artificial intelligence has moved decisively from experimentation to execution. Across industries, enterprises are no longer asking whether AI will reshape their business; but how fast they can operationalize it at scale. Yet as AI ambitions grow, a fundamental constraint keeps surfacing: traditional data center infrastructure is not designed for sustained, GPU-intensive workloads.
GPU data center decisions fail most often for one reason, that is the facility is treated as “space and power” instead of an AI production system. Treat it like a factory. Decide where workloads run (colo vs on-prem), size for today and 18–24 months out, design for training and inference as distinct operating modes, and demand proof on power density, thermal stability, and east–west networking.
Done right, GPU infrastructure delivers speed, predictability, and low-latency performance; done loosely, it becomes expensive capacity with inconsistent outcomes.
Recommended read: AI-ready infrastructure: How data centers are evolving to power AI workloads
The Top 3 Business Outcomes from GPU Data Center Solutions
At an executive level, the value of GPU data center solutions can be distilled into three outcomes that directly affect competitiveness.
Training time drops dramatically
Large AI models that once took weeks to train can be iterated in days and in some cases far faster when compute, interconnect, storage throughput, and cooling are engineered as one system. Faster training means faster experimentation, quicker validation, and shorter time-to-market for AI-driven products and services.
Cost predictability improves
AI initiatives often fail not because they lack value, but because infrastructure costs spiral unpredictably as workloads scale. GPU-ready data centers especially when architected for long-term use enable enterprises to plan capacity, energy consumption, and expansion with far greater accuracy by exposing the levers that actually move cost: utilization, power draw under sustained load, cooling efficiency at high density, software/ops overhead, and the cost of idle capacity.
Inference latency is reduced
enabling real-time or near-real-time decision-making. Whether it is fraud detection, quality inspection, or network optimization, low-latency inference is often the difference between AI as a theoretical capability and AI as a business-critical system.
The underlying problem is simple: AI projects stall when the data center cannot support GPU scale. GPU data center solutions address this by converting computational power into business velocity, cost control, and operational resilience.
Training vs Inference
why the economics and design choices diverge (and why it matters): Training is bursty, bandwidth-hungry, and sensitive to east–west fabric quality because distributed jobs generate heavy lateral traffic and frequent checkpointing. Inference is latency- and reliability-led, where predictable response times, multi-tenancy isolation, and cost-per-inference discipline become decisive.
CXOs should insist that the infrastructure plan explicitly separates these two modes; otherwise the organization overbuilds for one, underdelivers on the other, and loses the cost predictability it set out to achieve.
The CXO Decision Map: Four Questions That Define GPU Data Center Success
Approving a GPU data center investment is not a hardware decision.It is an architectural and financial one. The most effective way for CXOs to evaluate readiness is by asking the right questions early. These questions also form a natural framework for aligning infrastructure teams, finance, and risk stakeholders.
The first question is where AI models will run. Enterprises must decide whether GPU workloads will be hosted in colocated environments or in on-prem GPU pods. This choice directly impacts total cost of ownership, operational control, and scalability. Colocation often offers faster access to high-density infrastructure and shared resilience, while on-prem pods may provide tighter control for highly sensitive workloads. The wrong decision here can lock the organization into an inflexible cost structure for years.
Read about the benefits of colocation data center management for enterprises, here.
The second question is how large the GPU cluster needs to be today versus 18–24 months from now and what the “expansion trigger” will be. Under-sizing delays AI initiatives; over-sizing ties up capital in underutilized infrastructure. This is why right-sizing and modular scalability are critical. GPU data centers that support incremental expansion allow enterprises to scale in line with actual AI adoption rather than speculative demand.
The third question centers on peak-to-average load profiles. AI workloads are rarely uniform. Training jobs, inference spikes, and batch analytics create fluctuating power and thermal loads. Understanding these patterns is essential for making informed decisions about power density, cooling architecture, and PUE targets. Without this clarity, enterprises risk throttled performance or inefficient energy consumption.
Finally, CXOs must ask what governance and data residency constraints the facility must enforce. As AI models increasingly use regulated or sensitive data, the data center becomes a control point for compliance, auditability, and risk mitigation. GPU data center solutions must be designed to support these requirements at the physical and operational level.
Together, these questions form a decision map that aligns technical feasibility with business accountability.
Recommended read: The hidden risk of poor data center capacity management in the AI era
Industry Outcomes: Where GPU Data Center Solutions Deliver Tangible Value
The strongest case for GPU data center investments emerges when viewed through real-world industry outcomes.
Banking and financial services: GPU-powered real-time fraud detection systems significantly reduce inference latency. Faster scoring leads to fewer false positives, improved customer experience, and measurable reductions in fraud-related losses; all while operating within strict regulatory boundaries.
Retail and e-commerce: Personalization engines powered by GPU clusters enable near-real-time retraining of recommendation models. The result is higher conversion rates, increased average order value, and more responsive merchandising strategies that adapt quickly to customer behavior.
Manufacturing: Computer vision models deployed on GPU infrastructure drive quality inspection and predictive maintenance. Defect rates drop, yield improves, and unplanned downtime is reduced; directly impacting margins and throughput.
Telecom: GPU-driven network optimization supports real-time policy enforcement and traffic prediction. By processing massive telemetry streams efficiently, operators improve quality of service, reduce congestion, and optimize network investment.
Healthcare and pharma: GPU data centers accelerate imaging analysis and genomics while keeping sensitive patient or research data within controlled, compliant environments. Faster diagnostics and research cycles translate into better outcomes and faster innovation.
Across these industries, the pattern is consistent: GPU data center solutions convert AI potential into operational and financial results.
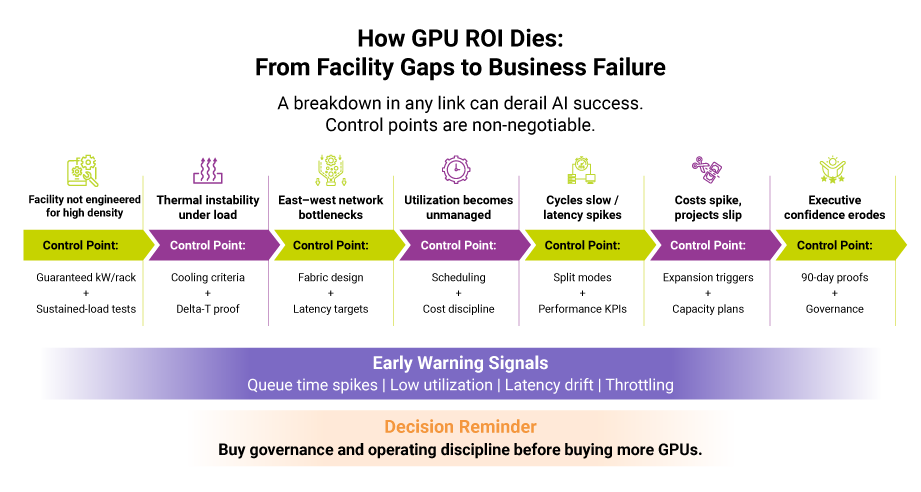
The Data Center Constraints That Kill GPU ROI and How to Vet a GPU Data Center Service Provider
Despite the promise, many GPU deployments fail to deliver expected ROI because the underlying data center is not designed for sustained GPU workloads.
A procurement-grade way to vet providers is “Ask / Prove / Commit” because GPU ROI dies in the gaps between marketing and engineering.
Power delivery: GPUs demand high and consistent power density. Ask what kilowatts per rack are guaranteed and what surge headroom is engineered for peak loads. Prove it with acceptance criteria and sustained-load test conditions. Commit it contractually so performance does not degrade at scale.
Thermal design: Advanced cooling often involving liquid cooling or hybrid approaches is no longer optional. Providers should be able to articulate delta-T guarantees and demonstrate how thermal stability is maintained under continuous GPU utilization. Ask how the facility behaves at sustained high density, not just at commissioning. Prove stability under continuous utilization. Commit operating ranges and escalation paths.
East–west network performance: Distributed training and parallel inference generate massive lateral traffic within GPU clusters. Intra-pod latency, along with support for technologies such as NVLink or InfiniBand, directly impacts training efficiency and model accuracy. Ask for target latency ranges and supported fabrics. Prove the design via reference architecture and documented limits. Commit to performance characteristics that match your training and inference modes.
Modular scalability and floor planning: Enterprises should evaluate how additional GPU pods can be integrated with minimal downtime and without reengineering the facility. Ask what expansion looks like in calendar time and change windows. Prove it with a repeatable pod blueprint. Commit expansion lead times and integration responsibilities.
These considerations separate GPU-ready data centers from facilities that merely host GPUs.
Recommended read: Data center security and compliance gaps that put AI workloads at risk.
A Practical Roadmap for Deploying GPU Data Center Solutions
Successful GPU adoption follows a disciplined, outcome-driven roadmap.
Enterprises typically begin by piloting a right-sized GPU pod around a high-impact use case, with clear success metrics tied to training speed, inference latency, or cost efficiency. This is followed by validating power and cooling performance in situ, ensuring thermal behavior aligns with design assumptions.
Next comes observability. Tracking GPU utilization, model throughput, and power consumed per training job allows leaders to tie infrastructure performance directly to business value. With this visibility, organizations can iterate on scaling policies — balancing persistent capacity with burst requirements — without compromising predictability.
The final step is governance. Model lifecycle management, data residency enforcement, and rollback mechanisms must be operationalized at the infrastructure level to support long-term AI maturity.
Why Sify Provides the Right Foundation for GPU Scale
For enterprises evaluating GPU data center solutions, the quality of the data center partner is as important as the GPUs themselves.
Sify Data Centers are engineered to support high-density, GPU-intensive workloads with purpose-built power architectures, advanced cooling systems, and modular scalability. With a pan-India footprint and carrier-dense connectivity, Sify enables enterprises to deploy GPU clusters that meet both performance and data residency requirements.
What CXOs should expect a serious partner to document in due diligence and what Sify is prepared to walk through transparently includes: sustained-load operating assumptions (power and thermal), expansion blueprints and lead times, east–west networking design options aligned to training and inference, observability coverage (utilization, throughput, power per workload), and the control posture required for regulated industries.
Equally important, Sify data center integrates infrastructure with network and managed services, allowing enterprises to focus on AI outcomes rather than operational complexity. Its facilities are designed to meet the needs of regulated industries, providing the physical and operational controls required for secure, compliant AI deployments.
For CIOs looking to scale AI with confidence, Sify Data Center solutions offer a stable, future-ready foundation. These solutions align infrastructure decisions with long-term business strategy.
AI strategy ultimately succeeds or fails at the infrastructure layer. GPU data center solutions are no longer optional; they are the backbone of enterprise AI execution. Organizations that invest early and architect wisely will gain not just faster models, but durable competitive advantage.
If you are planning a GPU buildout or expanding an existing on-prem AI footprint, engage Sify to map your training and inference requirements to a right-sized, modular pod plan with clear proof metrics and expansion triggers.
Connect with Sify experts and learn more about leveraging GPU data center solutions.






















")







")


")
")
 framework for software and product development.")
")
 standard specifically designed for the telecommunications industry")

 in public cloud environments")


















