



Table of contents
Credits: Published by our strategic partner Kaiburr
Effective Teams in a right environment under Transformative Leadership by and large achieves goals all the time, innovates consistently, resolves issues or fixes problems quickly.
DevOps is to primarily improve Software Engineering practices, Culture, Processes and build effective teams to better serve and delight the Users of IT systems. DevOps focuses on productivity by Continuous Integration and Continuous Deployment (CI-CD) to effectively deliver services with speed and improve Systems Reliability.
The productivity of a System is higher with high performance teams and slower with low performance teams. High performance teams are more agile and highly reliable. We can have better insights on Team performance by measuring Metrics.
DORA (DevOps research and assessment) with their research on several thousands of software professionals across wide geographic regions had come up with their findings that the Elite, High performance, medium and low performance can be differentiated by just the four metrics on Speed and Stability.
The metric ‘Mean time to restore(MTTR) ‘, is the average time to restore or recover the system to normalcy from any production failures. Improving on MTTR, Our teams become Elite and reduces the heavy cost of System downtime.

Measure MTTR
MTTR is the time measured from the moment the System fails to serve the Users or other Systems requests in the most expected way to the moment it is brought back to normalcy for the System’s intended response.
The failure of the System could be, because of semantic errors in the new features or new functions or Change requests deployed, memory or integration failures, malfunctioning of any physical components, network issues, External threats(hacks) or just the System Outage.
The failure of the running system against its intended purpose is always an unplanned incident and its restoration to normalcy in the least possible time depends on the team’s capability and its preparedness. Lower MTTR values are better and a higher MTTR value signifies an unstable system and also the team’s inability to diagnose the problem and provide a solution in less time.
MTTR doesn’t take into account the amount of time and resources the teams spend for their preparedness and the proactive measures but its lower value indirectly signifies teams strengths, efforts and Savings for the Organization. MTTR is a measure of team effectiveness.
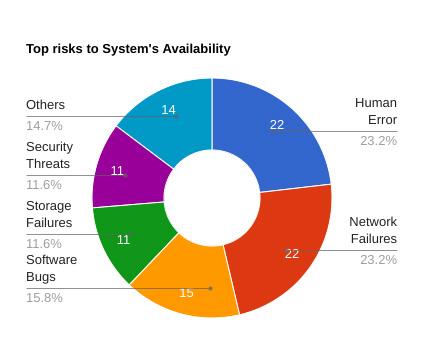
As per CIO insights, 73% say System downtimes cost their Organization more than $10000/day and the top risks to System availability are Human error, Network failures, Software Bugs, Storage failures and Security threats (hacks).
How to Calculate MTTR
We can use a simple formula to calculate MTTR.
MTTR, Mean time to restore = Total Systems downtime / total no. of Outages.
If the System is down for more time, MTTR is obviously high and it signifies the System might be newly deployed, complex, least understood or it is an unstable version. A system down for more time and more frequently causes Business disruptions and Users dissatisfaction. MTTR is affected by the team’s experience, skills and the tools they use. A highly experienced, right skilled team and the right tools they use helps in diagnosing the problem quickly and restoring it in less time. Low MTTR value signifies that the team is very effective in restoring the system quickly and that the team is highly motivated, collaborates well and is well led in a good cultured environment.
Well developed, elite teams are like the Ferrari F1 pit shop team, just in the blink of an eye with superb preparedness, great coordination and collaboration, they Change tyres, repairs the F1 Car and pushes it into the race. MTTR’s best analogy is the time measured from the moment the F1 Car comes into the pit shop till the moment it is released back onto the F1 track. All the productivity and Automation tools our DevOps teams use are like the tools the F1 pitstop team uses.

How to improve, lower MTTR
Going with the assumption that a System is stable and still the MTTR is considerably high then there is plenty of room for improvement. In the present times of AI, we have the right tools and DevOps practices to transform teams to high performance and Systems to lower MTTR. Reports of DORA says high performance teams are 96x faster with very low mean time to recover from downtime.
It seems they take very less time, just a few minutes to recover the System from failures than others who take several days. DevOps teams that had been using Automation tools had reduced their costs at least by 30% and lowered MTTR by 50%. The 2021 Devops report says 70% of IT organizations are stuck in the low to mid-level of DevOps evolution.
Kaiburr’s AllOps platform helps track and measure MTTR by connecting to tools like JIRA, ServiceNow, Azure Board, Rally. You can continuously improve your MTTR with near real time views like the following

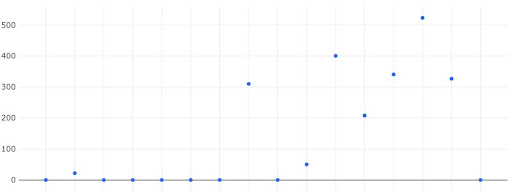
You can also track and measure other KPIs, KRIs and metrics like Change Failure Rate, Lead Time for Changes, Deployment Frequency. Kaiburr helps software teams to measure themselves on 350+ KPIs and 600+ Best Practices so they can continuously improve every day.
Reach us at marketing@sifycorp.com to get started with metrics driven continuous improvement in your organization.
Credits: Published by our strategic partner Kaiburr
Visit DevSecOps – Sify Technologies to get valuable insights






















")







")


")
")
 framework for software and product development.")
")
 standard specifically designed for the telecommunications industry")

 in public cloud environments")


















