



Table of contents
Artificial intelligence has moved from research labs to the boardroom agenda — and it is consuming infrastructure at a pace most data center companies were never designed to handle. GPU clusters demanding 100 kW per rack, training runs that push power grids to their limits, inference workloads requiring near-zero latency: these are exposing structural gaps that no amount of incremental upgrades will fix.
For CXOs making infrastructure decisions today, choosing the wrong data center partner doesn’t just slow down AI projects. It derails competitive positioning, inflates costs, and creates compliance exposure that boards increasingly cannot ignore.
What Makes AI Workloads Different from Traditional Enterprise Workloads?
A standard enterprise server rack draws 5–15 kW. A single rack of NVIDIA H100 GPUs configured for AI training can demand 60–130 kW or more. Multiply that across thousands of GPU nodes and the power, cooling, and network implications become extraordinary.
AI workloads split into two fundamentally different infrastructure demands. Training requires massive, sustained compute over days or weeks — high-bandwidth GPU interconnects, stable power, and aggressive cooling. A single power interruption mid-run can invalidate days of computation for . Inference, by contrast, needs burst elasticity, ultra-low latency, and continuous availability as models serve real-time predictions to end users and automated systems.
Legacy data center companies were architected around a different physics entirely — lower densities, air cooling, north-south network traffic, CPU-centric compute. The gap between what AI demands and what these facilities can deliver isn’t incremental. It’s architectural.
Why Many Data Center Companies Fail in the AI Era
- Infrastructure Not Designed for High-Density AI Compute
Most colocation facilities were built for rack densities of 5–15 kW. GPU clusters require 30–130+ kW per rack, with fundamentally different requirements for cable management, power distribution units, floor loading, and structural design. Data center companies that re-provision CPU-era racks for GPU workloads create what the industry calls “stranded capacity” — racks that are occupied but operationally underperforming because the facility can’t safely deliver the power and cooling those GPUs require.
The result: GPU utilization falls well below the 70–80% threshold needed to justify the hardware investment. The infrastructure — not the AI model — becomes the limiting factor.
Learn about data center colocation services. - Power Architecture Cannot Support AI Scale
AI workloads ramp from zero to full load in seconds, creating demand spikes that legacy UPS and power distribution systems struggle to absorb without voltage fluctuations. Facilities without high-voltage substation capacity, robust N+1 or 2N redundancy, and intelligent energy management expose enterprises to a specific and costly risk: a power event during a large training run doesn’t just cause downtime — it invalidates the entire job.Energy optimization matters equally. AI workloads running 24/7 consume enormous electricity. Without real-time load balancing and renewable energy integration, operational costs escalate rapidly — and enterprise ESG commitments become harder to honor. - Cooling Systems Fail Under Sustained AI Loads
Conventional hot-aisle/cold-aisle air cooling works reasonably well below 20 kW per rack. Above that threshold, the economics and physics break down. Data center companies that haven’t invested in liquid cooling — rear-door heat exchangers, direct-to-chip solutions, or full immersion cooling — cannot credibly support the next generation of GPU platforms, many of which are being designed with the assumption that liquid cooling is the default. - Network Bottlenecks Impact AI Performance
Traditional data center networks handle north-south traffic. AI training generates intense east-west communication between thousands of GPU nodes exchanging gradients and weights. Without high-speed interconnects such as InfiniBand or RoCE, and network topologies optimized for all-to-all GPU communication, distributed training jobs spend significant time waiting for data rather than computing — reducing GPU efficiency and extending timelines. - Poor Integration with Hybrid and Multi-Cloud Environments
Enterprise AI workloads span on-premises systems, colocation, and multiple cloud providers. Data center companies operating as isolated islands — without direct cloud on-ramps or workload orchestration capabilities — force enterprises into fragmented architectures that increase latency, raise data transfer costs, and complicate AI pipeline management. - Security and Compliance Not AI-Ready
AI introduces security challenges that most facilities weren’t designed to address: protecting training data containing sensitive customer records, safeguarding model weights that represent significant intellectual property, and providing the auditability that AI governance frameworks increasingly demand. Data center companies without robust data residency controls, sovereignty frameworks, and compliance certifications expose enterprise customers to regulatory risk that often isn’t visible until it’s too late.
The Business Impact: Why This Matters for CXOs
Infrastructure failure in the AI era translates directly into measurable business cost. Consider what’s actually at stake:
- GPU underutilization can destroy ROI fast. NVIDIA H100 GPUs cost $30,000+ per unit. Infrastructure limitations that keep utilization below 60% represent direct, ongoing financial waste.
- Downtime during training doesn’t just mean downtime — it may invalidate days of computation, delaying model development, and missing market windows for numerous data center companies.
- Competitive disadvantage compounds over time. Data center companies constrained by inadequate infrastructure iterate slower, experiment less, and deploy AI capabilities later than competitors who aren’t.
- ESG exposure is becoming a material boardroom risk, not just a reputational one. Facilities relying on carbon-intensive power and water-intensive cooling are increasingly scrutinized by investors and regulators alike.
How to Evaluate Data Center Companies for AI Readiness
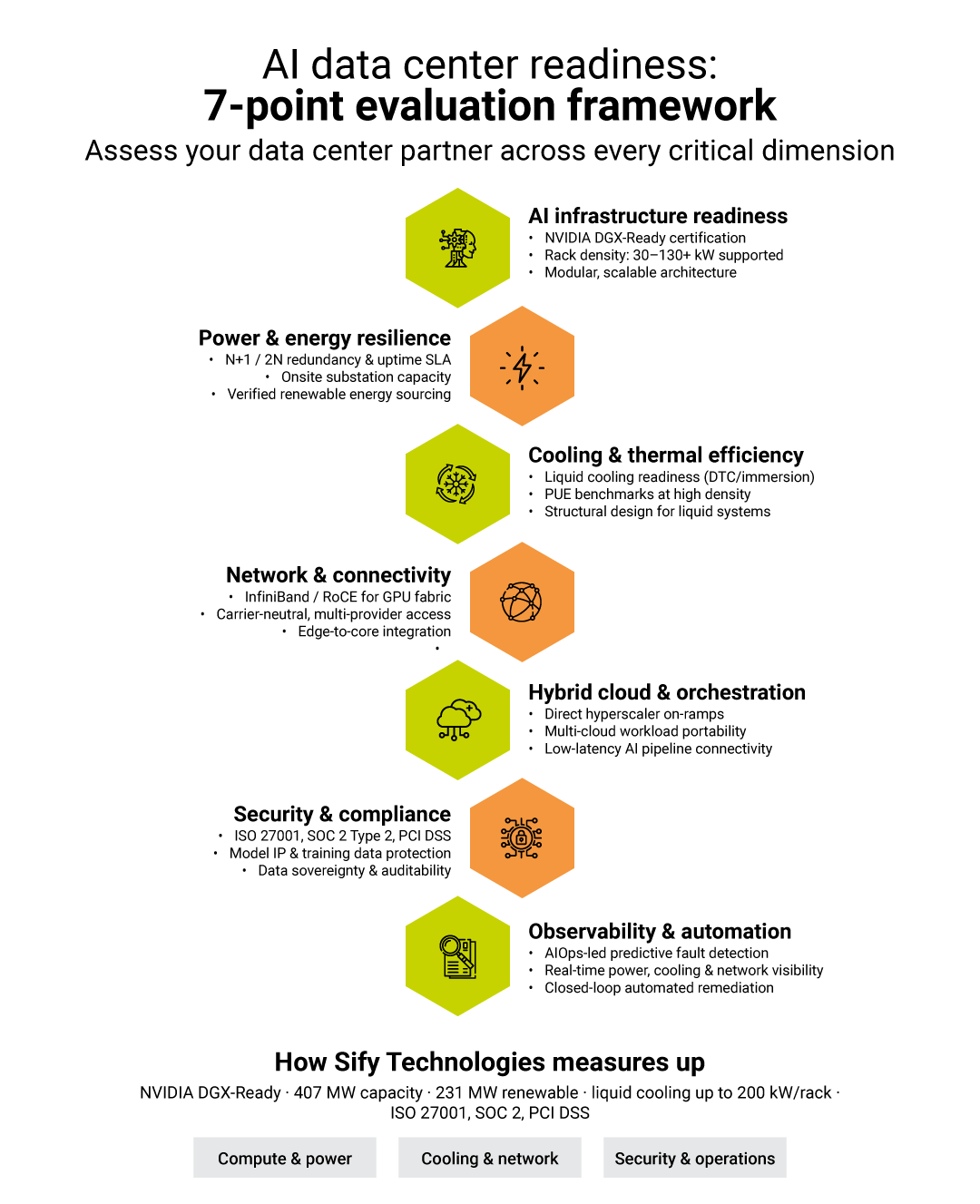
Not all AI-ready claims are equal. When assessing a data center partner for AI workloads, evaluate across seven dimensions:
- AI Infrastructure Readiness — Does the facility hold recognized certifications such as NVIDIA’s DGX-Ready designation? What is the maximum supported rack density, and can it scale beyond 100 kW/rack?
- Power and Energy Resilience — What redundancy level (N+1 or 2N) is provided? What proportion of power comes from renewable sources, and how is this verified?
- Cooling and Thermal Efficiency — Is liquid cooling available, and is the facility structurally designed to support it? What is the facility’s PUE (Power Usage Effectiveness) at AI-dense rack configurations?
- Network and Connectivity — Is the facility carrier-neutral? What high-speed interconnect options are available for GPU cluster communication?
- Hybrid Cloud and AI Orchestration — Are there direct, low-latency links to major hyperscalers? What workload portability and multi-cloud compatibility is supported?
- Security and Compliance — What certifications are held (ISO 27001, SOC 2 Type 2, PCI DSS)? Are there AI-specific governance capabilities including model IP protection and auditability frameworks?
- Observability and Automation — Is AIOps-based predictive monitoring in place? How are SLAs enforced and reported in real time?
7 ways to evaluate data center companies for Ai readiness
Three Key Features of Future-Ready Data Center Companies
The data center of the future is not a faster version of today’s facility. It represents a fundamental rethinking of infrastructure across every dimension — and the hardest problems are still being solved.
Security by Design, Compliance by Configurability
Future-ready data center companies embed security into the infrastructure architecture itself — not as an afterthought, but as a foundational design principle. For AI workloads, this means three things. First, training data security: cryptographic isolation, zero-trust access architectures, and hardware-level trust anchors that protect the sensitive data used to build AI models. Second, model IP and inference security: secure enclaves and hardware security modules that protect trained model weights against exfiltration, and infrastructure controls that prevent models from being reverse-engineered through adversarial queries. Third, auditability at the infrastructure level — immutable logs, provenance tracking, and attestation capabilities that compliance teams can rely on in actual regulatory proceedings.
The companion principle is compliance by intelligence: in a future-ready data center, compliance is no longer manually configured — it is continuously understood, enforced, and adapted by the system itself. Consider a global enterprise processing customer data across India, Europe, and the US. As regulations differ across these jurisdictions — covering data residency, privacy, and sovereignty — the data center automatically identifies where each dataset is permitted to reside and who is authorized to access it. If EU data is about to be stored or accessed outside permitted regions, the system instantly blocks or reroutes it without human intervention, while maintaining a real-time audit trail. As AI regulation matures globally — from the EU AI Act to India’s Digital Personal Data Protection Act — this kind of autonomous, intelligence-driven compliance will move from a differentiator to a baseline requirement.
Read: Data center security and compliance gaps that put AI workload at risk
Rethinking Cooling: The Water Problem Nobody Is Solving Fast Enough
The water consumption of large-scale AI data centers is becoming one of the defining infrastructure controversies of this decade. Research estimates that U.S. data centers consumed 17 billion gallons of water for cooling in 2023 — a figure set to multiply sharply as AI workloads scale. Communities near major hyperscale facilities have raised serious concerns about competition with residential water needs, and regulators in multiple markets are beginning to respond.
Conventional liquid cooling using water is a bridge technology, not a destination. The industry urgently needs commercially viable alternatives: advanced dielectric fluids for immersion cooling that eliminate water from the loop entirely, phase-change materials that absorb and release heat without continuous fluid flow, and hybrid dry-cooling systems that minimize water dependency. Each of these directions is in active development, but none has yet reached the cost and scale maturity needed for mainstream hyperscale deployment. This is one of the most consequential open engineering challenges in data center infrastructure today — and future-ready operators are those actively investing in the research and transition, rather than waiting for the problem to become unavoidable.
Read: Data center cooling for AI workloads: Why liquid cooling is becoming non-negotiable
Rethinking Power: Toward Sustainable, Dense Energy
AI data centers are placing extraordinary pressure on power grids. A large-scale AI facility can consume as much electricity as a city of 100,000 households. Renewable energy contracts are an essential first step, but solar and wind face intermittency challenges that sustained AI training workloads cannot tolerate.
The longer-term power trajectory will require a portfolio approach. Advanced grid storage can buffer renewable intermittency and provide the stable baseline AI workloads demand. Small Modular Reactors (SMRs) — nuclear fission-based systems advancing toward commercial viability — represent a compelling path to carbon-free, dense baseload power at data center scale, and several major hyperscalers are already exploring SMR partnerships. Further out, fusion energy research has seen genuine technical progress in recent years, and commercial fusion power would fundamentally change the energy economics of AI infrastructure. These are not idle speculations — they are active investment and research priorities precisely because the stakes are so high. The transition to sustainable, high-density power for AI is a strategic and geopolitical question as much as an engineering one.
Read: How AI data centers are evolving to power AI workloads
How Sify Technologies Supports AI-Ready Data Center Infrastructure
As enterprises across India and the Asia-Pacific region accelerate their AI ambitions, Sify Technologies has invested ahead of the curve — building data center infrastructure that is genuinely ready for the demands of today’s AI workloads and the ones coming next.
Sify operates 14 data centers across India with AI data center expansion including 20 AI inference facilities across secondary markets. Sify is India’s only provider certified under NVIDIA’s DGX-Ready Data Center program across multiple campuses — validating GPU rack density support up to 130 kW per rack and beyond. The Rabale hyperscale campus in Navi Mumbai is designed for up to 377 MW of IT capacity across 12 towers, with built-to-suit options for enterprises with specific AI infrastructure requirements.
On power and sustainability, Sify has contracted over 231 MW of renewable energy and operates dedicated 220 kV onsite substations at key campuses — providing the stable, redundant, high-density power that GPU workloads demand. On cooling, Sify is India’s first NVIDIA-certified DGX-Ready provider with liquid cooling capability, supporting both air and liquid configurations up to 200 kW per rack.
On security and compliance, Sify holds ISO 27001, ISO 27017, ISO 27018, SOC 2 Type 2, SOC 1 Type 2, and PCI DSS certifications. For India-based enterprises navigating the Digital Personal Data Protection Act, Sify’s India-anchored infrastructure provides data residency and sovereignty controls that keep AI workloads compliant without the complexity of cross-border data flows. Intelligent operations across the portfolio are powered by AIOps-led monitoring and automation — with 10 levels of physical security and a proven track record of 100% uptime SLA adherence.
Why the Right Data Center Company Is Now a Strategic Decision
For most of the past two decades, selecting a data center provider was primarily a procurement decision — focused on uptime, cost per rack, and location. That era is over.
In the AI era, your data center partner is a strategic enabler of competitive capability. The speed at which you can train models, the cost at which you can run inference at scale, the compliance posture that lets you deploy AI in regulated markets, the resilience that protects AI pipelines from disruption — all of these are direct functions of the infrastructure decisions you make today.
The shift that matters most: data center capacity is no longer the primary variable. Capability is — the ability to deliver AI-optimized compute, sustainable power, advanced cooling, seamless connectivity, robust security, and increasingly autonomous operations. That capability is what separates infrastructure that accelerates the AI agenda from infrastructure that quietly constrains it.
The question for every CXO has changed. It’s no longer “Do we have enough data center capacity?” It’s “Does our data center infrastructure have what it takes to make our AI strategy succeed?”
Explore Sify Technologies’ AI-ready data center capabilities at:
https://www.sifytechnologies.com/data-center/






















")







")


")
")
 framework for software and product development.")
")
 standard specifically designed for the telecommunications industry")

 in public cloud environments")


















